HB DEID
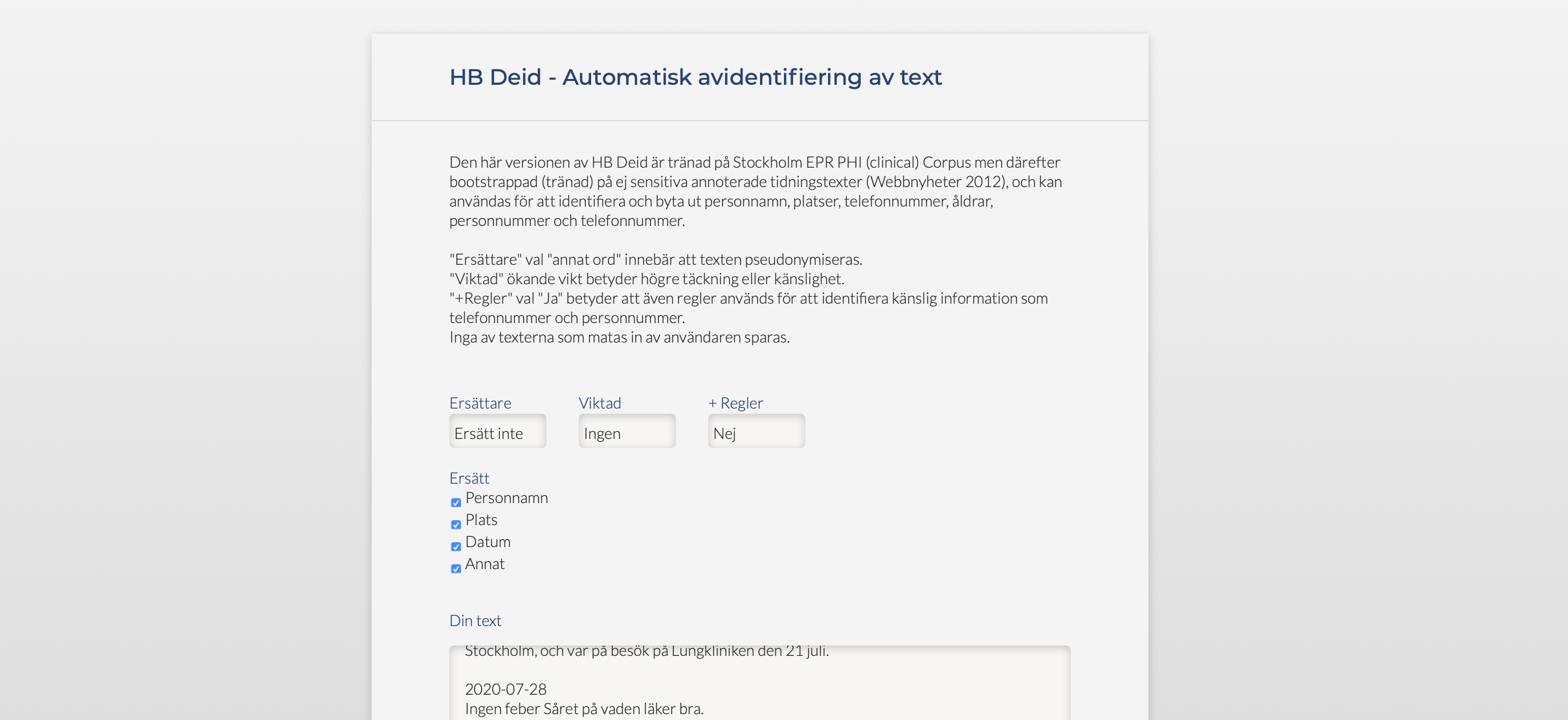
HB Deid is a de-identification system for Swedish electronic health records. A demo is available here (in Swedish). It uses a Named Entity Recognition model trained on web text instead of sensitive data. The module for obscuring information deemed as potentially sensitive is similar to the real version.
About me
Hanna Berg was a research assistant in the Clinical Text Mining Group at the Computer and Systems Sciences Department, Stockholm University. She was part of the DataLEASH project, with Hercules Dalianis as research supervisor.
Publications
The Impact of De-identification on Downstream Named Entity Recognition in Clinical Text
Berg, H., A.Henriksson and H. Dalianis. (2020). In Proceedings of the 11th International Workshop on Health Text Mining and Information Analysis. Presented at Louhi 2020, in conjunction with EMNLP 2020, pdf.
A Semi-supervised Approach for De-identification of Swedish Clinical Text
Berg, H. and Dalianis, H. (2020). In Proceedings of The 12th Language Resources and Evaluation Conference, pages 4444–4450, Marseille. Association for Computational Linguistics. pdf.
Building a De-identification System for Real Swedish Clinical Text Using Pseudonymised Clinical Text
Berg, H., Chomutare, T., and Dalianis, H. (2019). In Proceedings of the Tenth International Workshop on Health Text Mining and Information Analysis (LOUHI 2019), in conjuction with Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 118–125, Hong Kong. Association for Computational Linguistics. pdf.
Augmenting a De-identification System for Swedish Clinical Text Using Open Resources and Deep Learning
Berg, H. and Dalianis, H. (2019). In Proceedings of the Workshop on NLP and Pseudonymisation, in conjunction with the 22nd Nordic Conference on Computational Linguistics (NoDaLiDa), pages 8–15, Turku, Finland. Linköping Electronic Press. pdf.
Presented work
Papers or abstracts presented at conferences, but not published.
Improving Named Entity Recognition and Classification in Class Imbalanced Swedish Electronic Patient Records through Resampling
Grancharova, M., Berg, H. and H. Dalianis. Presented at The Eight Swedish Language Technology Conference (SLTC-2020). 2020, November 27.
De-identification of Clinical Text for Secondary Use: Research Issues
Berg, H., Henriksson, A., Fors, U. and Dalianis. H. Presented at the Healthcare Text Analytics Conference (HealTAC), 2020, April 23.
Projects
DataLEASH: LEarning And SHaring under Privacy Constraints
The main objective of DataLEASH is to develop and analyze data analysis tools with disclosure control based on provable guarantees, for learning and sharing in an adversarial setting, both in terms of theoretical results and application to concrete scenarios.

Hanna Berg
Former research assistant
email – hanna.berg@dsv.su.se